AWS mostra como levar agentes para SRE e sugere que operações autônomas podem sair do slide para o plantão
Há muito tempo as equipes de operação convivem com um paradoxo irritante: monitoramento gera sinais demais, mas entendimento útil chega tarde demais. A promessa de “AIOps” tentou resolver isso com regras, dashboards e um pouco de ML, mas raramente mudou de fato a experiência do plantão. O post publicado pela AWS em 3 de junho de 2026, “How to build self-driving AI operations on Amazon Bedrock at scale”, é interessante justamente porque tenta empurrar essa conversa para um nível mais operacional. Em vez de falar genericamente de IA para observabilidade, a empresa mostra uma arquitetura concreta para detectar problemas, ajustar alarmes, classificar incidentes e abrir casos automaticamente.
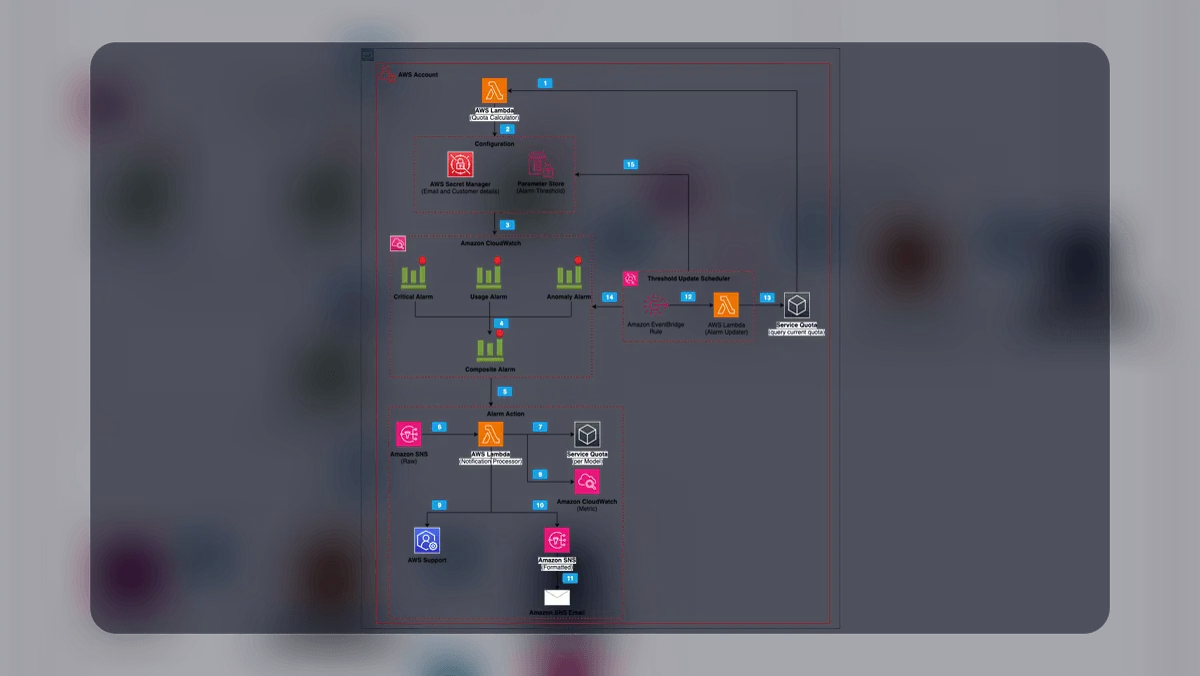
O nome da solução apresentada no artigo é Bedrock Ops Alert. A proposta é funcionar como uma camada de monitoramento automatizado em três níveis, combinando Amazon Bedrock, CloudWatch, Lambda e lógica de suporte operacional. O ponto principal não é “substituir SREs”, e sim reduzir o trabalho mecânico de triagem e encaminhamento que consome muito tempo antes da parte realmente humana de diagnóstico e decisão. Em empresas onde incidentes se repetem com ruído alto, isso pode representar um ganho relevante.
O que aconteceu
No post oficial, a AWS descreve o Bedrock Ops Alert como uma solução automatizada de monitoramento em três camadas. Segundo a empresa, ela detecta problemas operacionais, ajusta limites de alarme dinamicamente, classifica alarmes por categoria, cria casos de suporte contextualizados, evita duplicação de tickets quando já há caso aberto do mesmo tipo e notifica equipes de AI SRE com mais contexto. Fato confirmado: não é apenas um anúncio conceitual; há uma arquitetura explícita pensada para implantação.
Esse tipo de publicação tem um tom diferente de press releases clássicos, mas isso não reduz sua importância. Inferência plausível: a AWS está usando posts técnicos para empurrar seu enquadramento da próxima fase de operações em nuvem. A ideia de “self-driving AI operations” funciona como narrativa para dizer que observabilidade, classificação e resposta operacional devem migrar de sistemas predominantemente humanos para fluxos em que agentes fazem a primeira grande parte do trabalho.
A técnica por trás
O aspecto técnico mais importante é a noção de monitoramento em camadas. Em vez de tratar cada alarme como evento isolado, a arquitetura combina ajuste de limiares, categorização e geração de contexto acionável. Isso reduz dois problemas clássicos: falso positivo por threshold mal calibrado e perda de tempo com tickets redundantes ou pobres em informação. Quando a solução evita abrir um novo caso se já existe um não resolvido da mesma categoria, ela introduz memória operacional na automação, o que é crucial para não transformar IA em fábrica de ruído.
Também vale notar que a solução foi desenhada em torno de serviços gerenciados da AWS, especialmente Bedrock, Lambda e CloudWatch. Isso sugere um caminho em que agentes operacionais não são produtos isolados, mas composições de serviços de nuvem com LLMs, regras e integrações de suporte. O ganho potencial está menos no modelo “bruto” e mais na capacidade de costurar contexto, histórico e ação com baixa fricção.
Por que isso importa
Na prática, isso importa porque plantões de operação continuam sofrendo com excesso de eventos pouco priorizados. Mesmo equipes maduras gastam tempo demais entendendo se um alarme é sintoma, causa ou ruído repetido. Se uma camada automática consegue agrupar, classificar e abrir o caso certo com contexto certo, a qualidade do trabalho humano sobe. A equipe gasta menos energia com burocracia e mais com remediação real.
Também há um impacto econômico e organizacional. Fato confirmado: a AWS está mostrando um caminho para automatizar parte do workflow de SRE com IA integrada à própria nuvem. Inferência: isso reforça a aposta de que o próximo grande caso de uso corporativo de agentes não será só coding, mas também operações contínuas. Em ambientes grandes, cada minuto economizado na triagem de incidente multiplica valor em disponibilidade, foco e custos evitados.
O futuro que isso antecipa
O cenário plausível é uma transição gradual para operações assistidas por agentes em vários níveis: ajuste de thresholds, detecção de anomalia, contextualização de incidentes, proposta de remediação e talvez, em casos mais controlados, execução automática de ações reversíveis. O “self-driving” completo ainda exige muita cautela, mas a primeira fase já parece suficientemente madura para ganhar espaço em organizações que sofrem com escala operacional.
Ao mesmo tempo, há perguntas importantes. Como garantir que a automação não esconda sinais raros? Como auditar decisões do agente em ambientes críticos? Como equilibrar redução de ruído com sensibilidade adequada? O risco clássico de AIOps continua válido: quando o sistema tenta limpar demais o painel, ele pode esconder justamente o evento improvável que mais importa. O futuro bom dessa abordagem depende de camadas de revisão, explicabilidade e mecanismos claros de fallback humano.
O que observar
Vale observar adoções reais e se a AWS transforma esse padrão arquitetural em produto mais empacotado. Também será importante acompanhar como a solução lida com categorias de incidente muito diferentes entre si, porque padronização excessiva pode quebrar em operações complexas. Outra métrica relevante é confiança do time: SREs só delegam mais para a automação quando ela prova consistência sob pressão.
O post da AWS não significa que operações autônomas já chegaram plenamente. Mas ele mostra algo mais valioso do que slogan: uma arquitetura concreta para começar. Em um setor cansado de promessas vagas sobre observabilidade inteligente, isso já é um avanço considerável.
Fontes
- https://aws.amazon.com/blogs/machine-learning/how-to-build-self-driving-ai-operations-on-amazon-bedrock-at-scale/
- https://aws.amazon.com/blogs/machine-learning/